
Models. EML in ML
Three weeks ago hype erupted around the EML function. Three articles appeared almost at once. The first stated that all we need is a "two buttoned calculator", one button for "1", one for "EML" and that's enough to express everything we need to describe the world around us. Here EML(x, y) = exp(x) - ln(y). The second applies this approach to model battery charge cycle, the third - mixes traditional neural-network elements with a new gate.
I have mixed feelings here. On the one hand, intuition says that to be useful, these trees have to be really high. Like, 10 or 20 nodes. Too much for brute force. On the other hand, usual optimization methods do not just work out of the box. Backpropagation on tree structures - no. Gradient descent over a correct bracket sequence - no. To be honest, even conversion between EML notation and usual symbolic notation is a pain in the a... neck.
Then I had a thought. An EML expression is an expression like eml(eml(1, x), 1). First of all, we can see that there is always "eml(", so we can just use "(". This way it becomes "((1x)1)". Looks interesting. In the one-variable case, we have only four token types to encode all EML expressions: (, ), 1, and x. Would it be beneficial for transformers to have only four tokens to predict? Interesting thought, but not for this post. Maybe later...
But now we are ready to understand the cryptic expression from the previous post. ((1 x) ((1 1) x)) is a function, encoded by EML notation. You can decipher it recursively. (1 1) is (exp(1) - ln(1)) = e. Then ((1 1) x) = (e x) = exp(e) - ln(x) = e**e - ln(x). And so on.
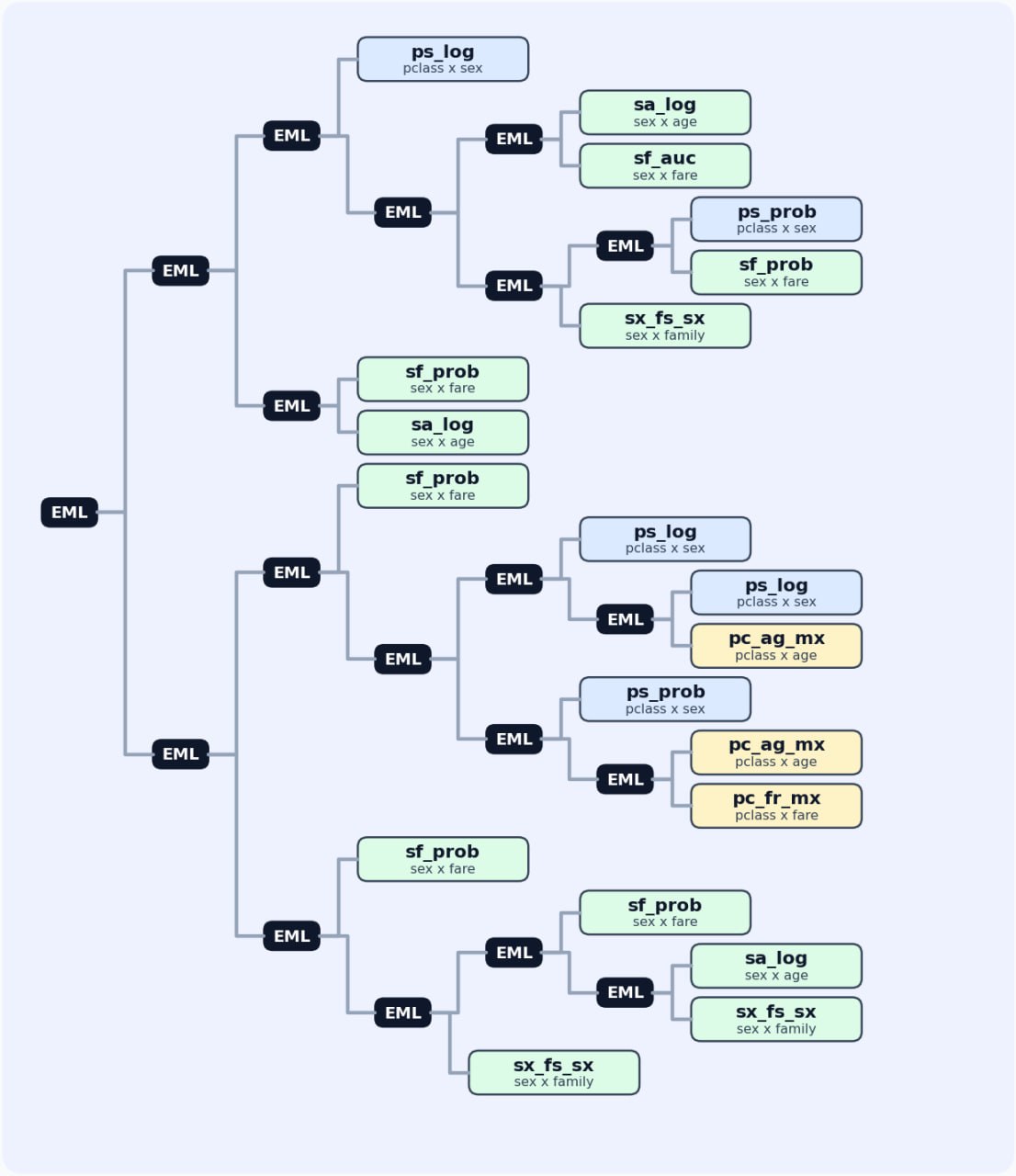
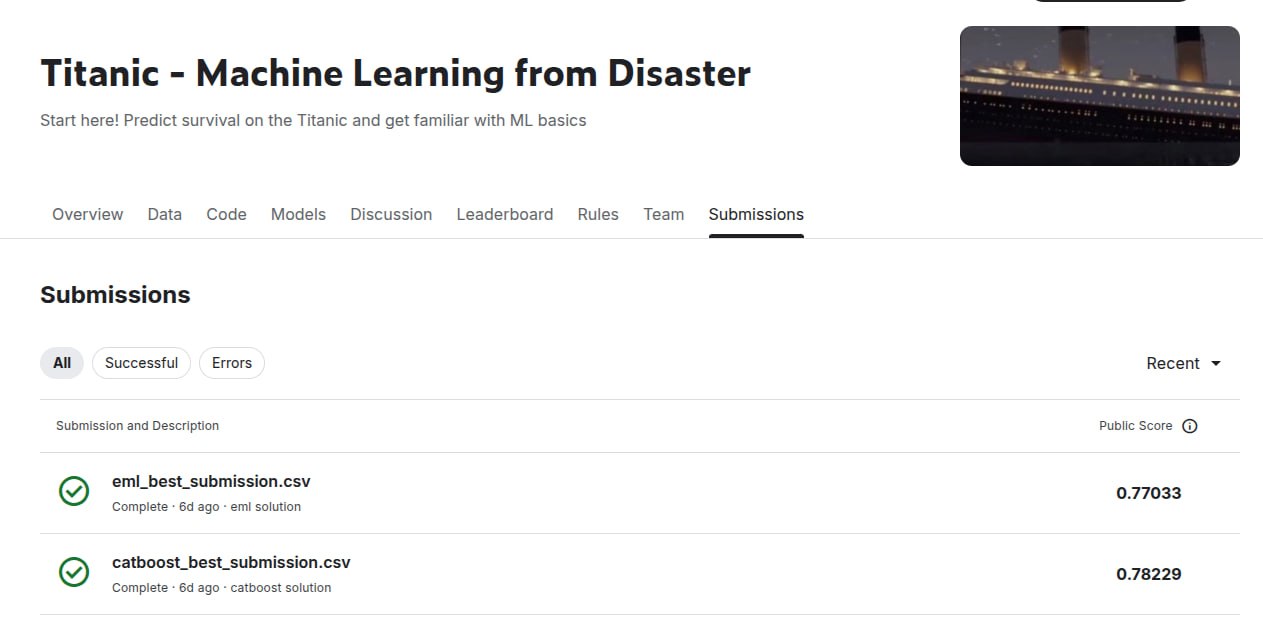
I conducted an experiment. I took the Titanic dataset and normalized all features to be in the range [0, 1]. Then I ran selection of 3-level EML trees with the best ROC AUC over pairs of features. On the top of these candidates, I ran a genetic algorithm to find the best combination by ROC AUC and logloss. The result is an EML tree which solves the Titanic dataset almost as well as the specialized CatBoost package does.
This exercise is for joke only, because this algorithm is extremely computationally expensive and can't be scaled at all.
But I totally think that it was worth it. As a result, we have something as precious as a talking frog: an EML tree which solves the Titanic dataset, and the understanding that notation like (1(x (x (1 1)))) enumerates mathematical expressions and therefore, ML models.
👉👉Know someone who likes math, ML, and weird experiments? Share this post with them!👈👈
To check:
🛸 EML tree for Titanic
(((ps_log ((sa_log sf_auc) ((ps_prob sf_prob) sx_fs_sx))) (sf_prob sa_log)) ((sf_prob ((ps_log (ps_log pc_ag_mx)) (ps_prob (pc_ag_mx pc_fr_mx)))) (sf_prob ((sf_prob (sa_log sx_fs_sx)) sx_fs_sx))))
🤿 GitHub - code of EML solving the Titanic