Titanic: family bonds
Nowadays, it is hard to imagine an ML person without a Jupyter notebook. So let’s think a little outside the box and consider other options.
Quite recently, I discovered an interesting option for CSV table analysis. It consists of two instruments: DBeaver and DuckDB. The former is a Swiss army knife for database access, and the latter is a plugin that is quite powerful, or so I was told, but can also be used to open CSV files.
So, you can create a new DuckDB connection in DBeaver (ducks and beavers, yeah...), select the titanic.csv file you got from Kaggle, and start running queries.
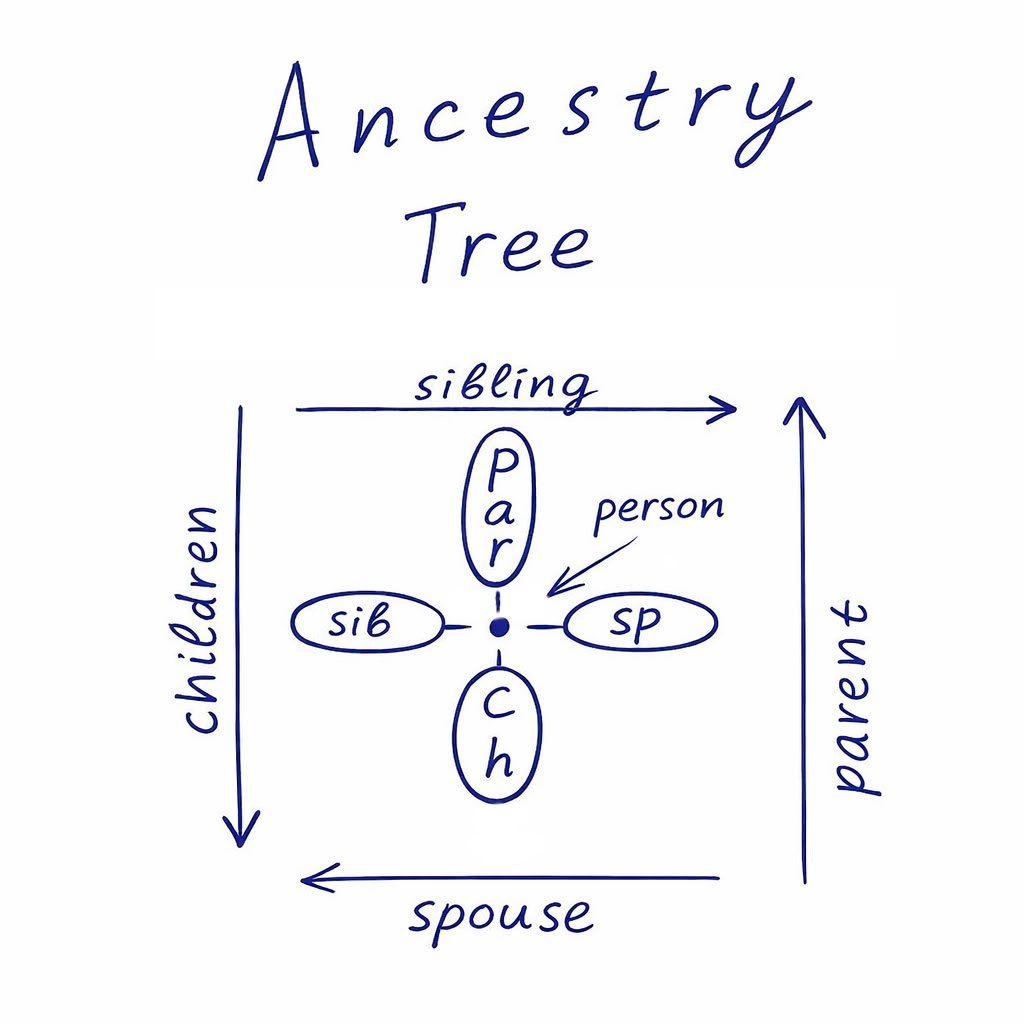
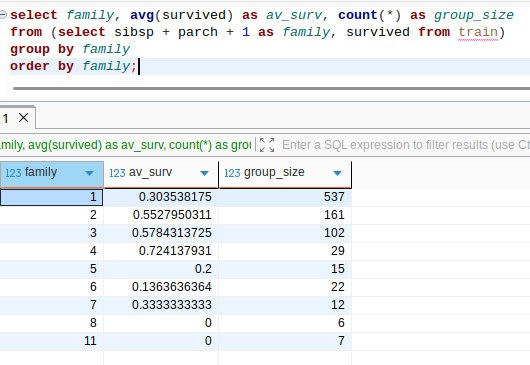
SibSp is a factor, so to speak, horizontal in the ancestry tree. It is the sum of siblings and spouses. Parch is vertical in these coordinates: parents and children.
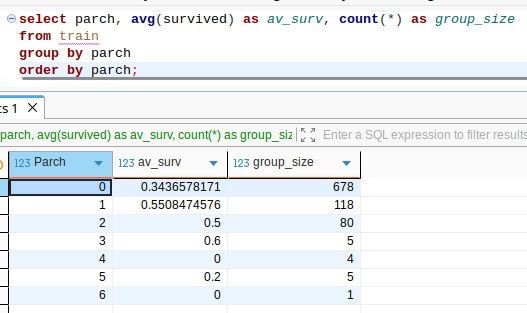
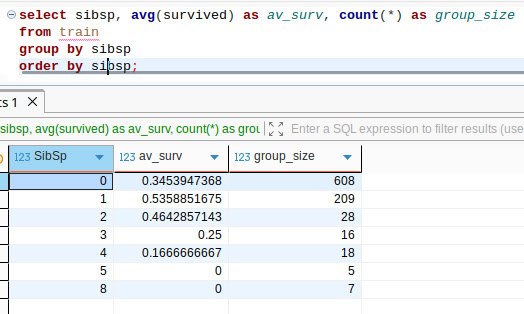
The first two queries show us the strength of these factors separately. The third uses the nested query technique to produce a derived factor, family size. One can see that these factors are useful, but the derived factor gives a stronger depletion/enrichment effect. This time, we were lucky enough to engineer a new feature.
I would say that family sizes 2, 3, and 4 vote for survival; the others vote against it.