GBDTE: LogLoss-датасет
Мой подход с синтетическим набором данных MSE оказался успешным. Я создал его, и все эксперименты дали мне вполне ожидаемые результаты. Следующий рубеж — синтетический набор данных для тестирования функции логарифмических потерь.
Это важно для меня, потому что я начал с этой проблемы и хочу четко продемонстрировать, особенно на синтетических данных, что этот подход работает и что мы можем улучшить стабильность нашей модели, включив время.
Итак, я начал с того же подхода, который мы с другом использовали почти десять лет назад в нашей статье. Мы создали датасет, где все бинарное: и таргет, и признаки для сплитов. То есть значения только 0 или 1. Секретный ингредиент - время: t в диапазоне от 0 до 1 и временной базис [1, t]. Цель модели - найти веса w1 и w2, чтобы оценка (w1*1 + w2*t) минимизировала logloss.
Чтобы было интереснее, добавляем зависимость статистики датасета от времени. Я решил делать time-dependent lift.
Давайте коротко про термин. Можно посчитать средний таргет по всему датасету и по подмножеству, выбранному конкретным признаком. Lift - это отношение второго к первому. Идея в том, чтобы lift менялся со временем.
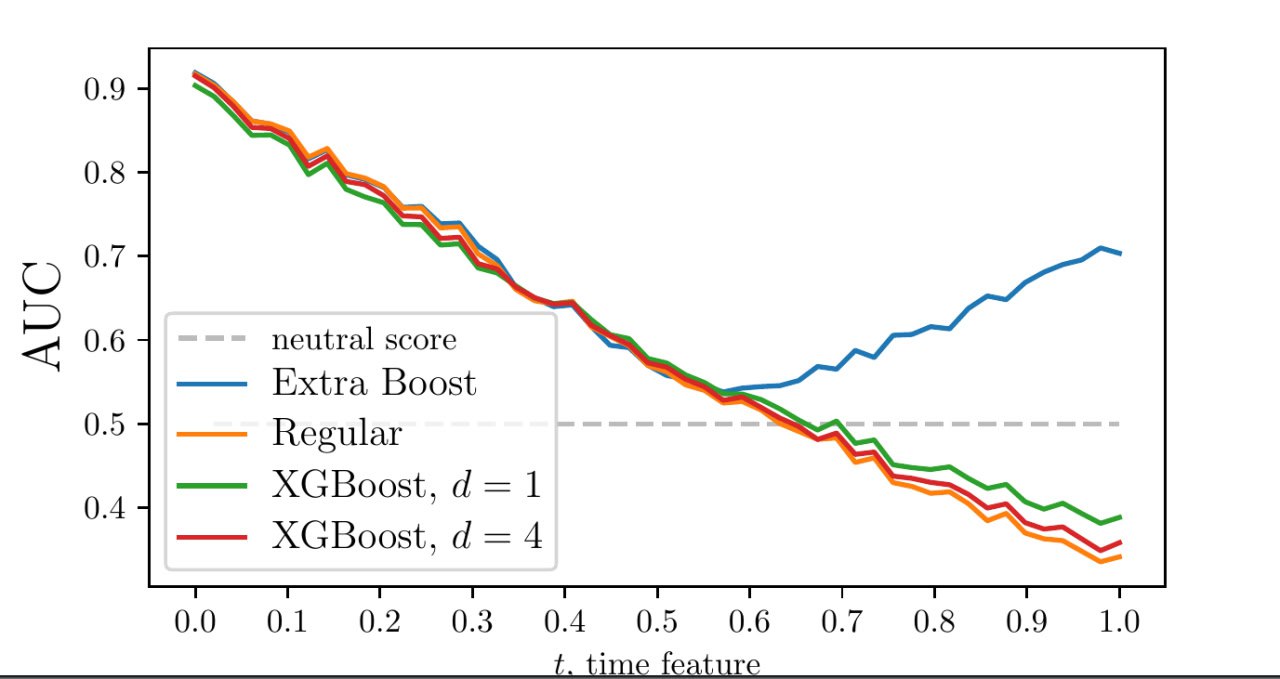
Есть две группы статических признаков: f1..f8 с растущим lift и f9..f16 с падающим lift. В исходной постановке картина была немного асимметричной, и точки, где lift равен 1, для групп не совпадали. В этот раз я задал зависимости gamma_up = 0.5 + t и gamma_down = 1.5 - t.
Я ожидал картину, похожую на ту, что была в статье, но в этот раз получилось иначе. Пока не понимаю, почему, и сейчас глубоко копаю теорию time-dependent бинарных датасетов.