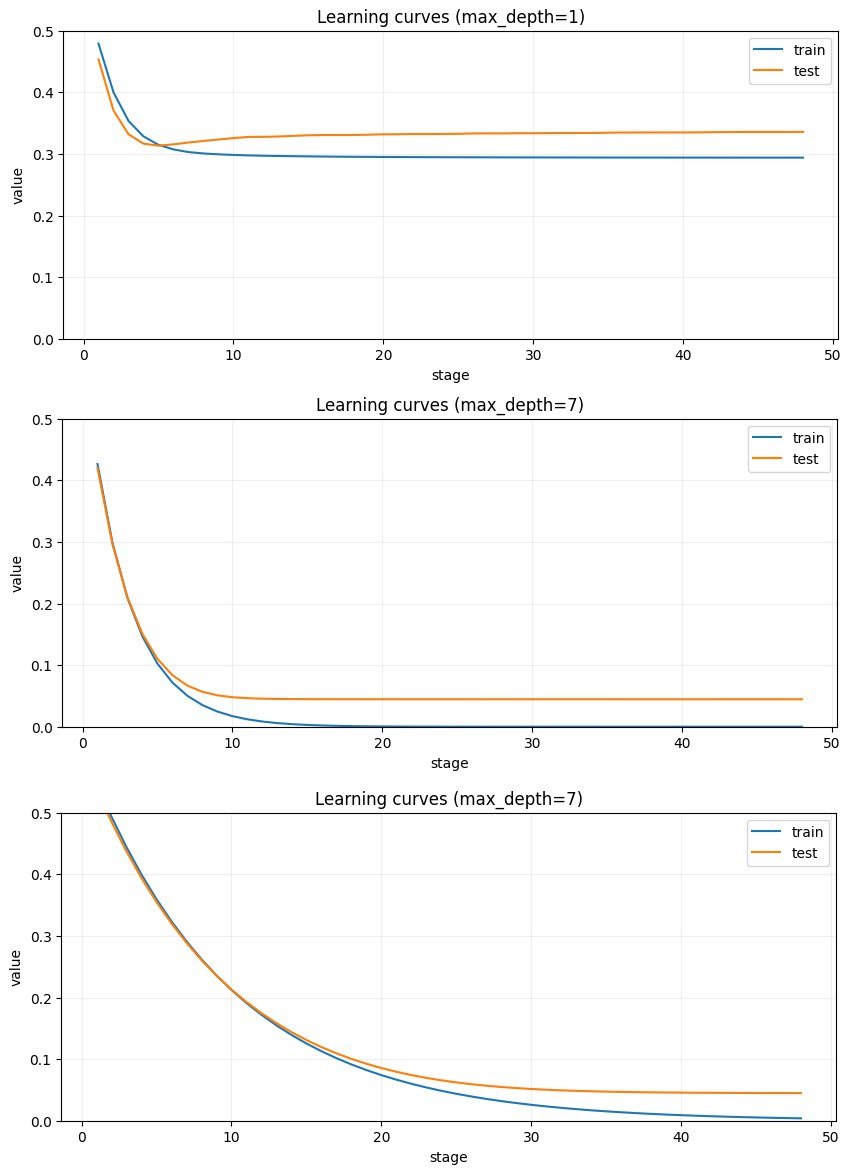
Большой MSE-датасет. Глубина деревьев.
В большом датасете 128 групп. Чтобы различать их идеально, нужно ровно 7 бинарных разбиений. Почему? Каждый новый уровень дерева заменяет один лист на два. Если начать с корня и построить 7 уровней, получим 128 листьев - по одному на каждую группу.
Это хорошо иллюстрирует известную фразу про GBDT: «Глубина дерева - это число факторов, которые должны сработать совместно». Я часто ее слышал, но в реальных датасетах это обычно остается теорией: заранее неясно, сколько факторов должно объединяться.
В этом датасете точное число таких факторов известно заранее - 7, и интуицию можно проверить напрямую. Эту историю и показывают три графика. На верхнем деревья глубиной всего 2. Модель ограничена по выразительности: сначала обе кривые (train и test) падают, затем test начинает расти из-за переобучения на шум, а train при этом не удается дожать до хорошего качества. Это то же самое, что мы видели в предыдущем посте на графике предсказаний по train.
На нижнем графике видно, что при глубине 7 MSE сильно ниже, и соответствие между датасетом и предсказаниями заметно лучше.
Третье изображение про learning rate. Для верхних графиков lr = 0.3, для нижнего lr = 0.1. Кривые становятся менее крутыми, но асимптоту train это почти не улучшает. Если на ранних шагах точки ошибочно попали не в те группы, потом это уже трудно исправить.