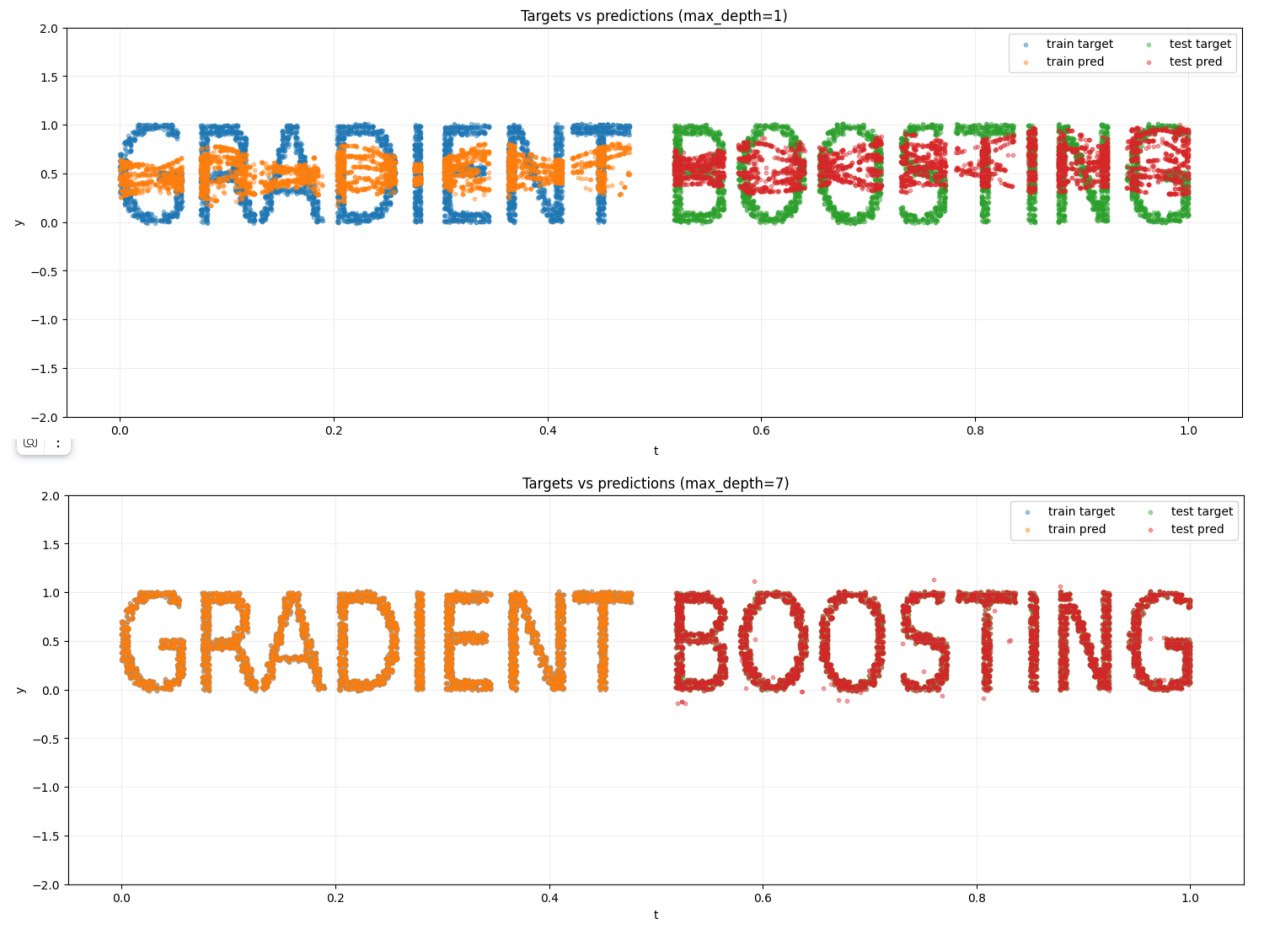
Большой набор данных MSE для GBDT
В предыдущем посте я показал маленький датасет, на котором видно, как работает GBDT. Теперь хочу показать большой: в нем 10 000 точек.
Меня не устроило качество текста в маленьком датасете, поэтому я повторил алгоритм и в этот раз взял больше точек.
Ручкой расставлять столько точек сложно, а вот «железного друга» попросить сэмплировать их очень легко.
Тут я неожиданно застрял: мне не понравились шрифты. Обычно в Linux я о них почти не думаю, но здесь захотелось чего-то «интересного» - наверное, жирного и округлого. Начал гуглить онлайн-инструменты для перебора шрифтов и какое-то время попадал только на бесполезные страницы. В итоге все равно пришел к очевидному варианту: fonts.google.com.
Дальше дело пошло быстро. «Железный друг» отрендерил надпись и раскидал по ней 10 000 точек. Разделить их на компоненты тоже оказалось несложно. В итоге получился датасет из 10 000 точек, разбитых на 128 групп.
На этом пока остановимся. Связь между высотой деревьев и числом групп здесь очень интересная. Разберу ее спокойно и подробно в следующем посте.