


Абсолютное зло параметров по умолчанию
Параметры по умолчанию — это зло. Серьезно. Это очень удобное зло — настолько удобное, что оно залезло в мою библиотеку.
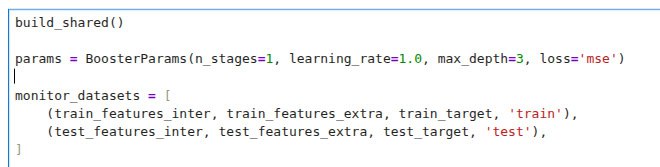
На первом изображении есть призыв к обучению модели с помощью:
🐴n_stages = 1: один шаг бустинга (одно дерево)
🐴learning_rate = 1.0: сразу прыгаем в минимум текущей параболы
🐴max_depth = 3: используем три статических признака для разделения объектов на группы (8 групп)
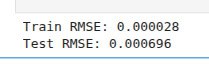
И, кажется, это все. Так почему же мы имеем ненулевые потери? Без понятия.
Спасибо ChatGPT. Я загрузил набор данных и объяснил гипотезу: есть что-то странное, попробуй найти наилучшее приближение таргета в каждой группе, заданной статическими признаками. Потом пошел чистить зубы. Когда вернулся, ответ уже был готов: с датасетом все в порядке, MSE около 1e-32, то есть ноль в рамках double precision.
Я почесал затылок, заархивировал весь репозиторий, загрузил его в ChatGPT и попросил: «Найди источник 0.0007 RMSE». Потом занялся своим ежедневным английским. Через пятнадцать минут ответ был готов:
ЧЕРТОВЫЕ ПАРАМЕТРЫ ПО УМОЛЧАНИЮ
Мой железный друг откопал вот такую строчку:
🐴reg_lambda: float = 1e-4
Этот параметр регуляризации L2 заставил модель пропускать точки в наборе обучающих данных и вызвал это небольшое, но досадное несоответствие.
Я могу представить, как пытаюсь это отладить. Мой железный друг сэкономил мне около двух дней на повторной проверке разных частей моей системы. И, наверное, все бы снова поставилось на паузу.