EGBDT LogLoss — кривые обучения
Про синтетический LogLoss-датасет уже было два поста. Давайте разберем следующий эксперимент.
В датасете две группы статических признаков:
📈 f1…f8: признаки с растущим uplift
📉 f9…f16: признаки с падающим uplift
И есть дополнительные признаки [1, t] для учета bias и тренда.
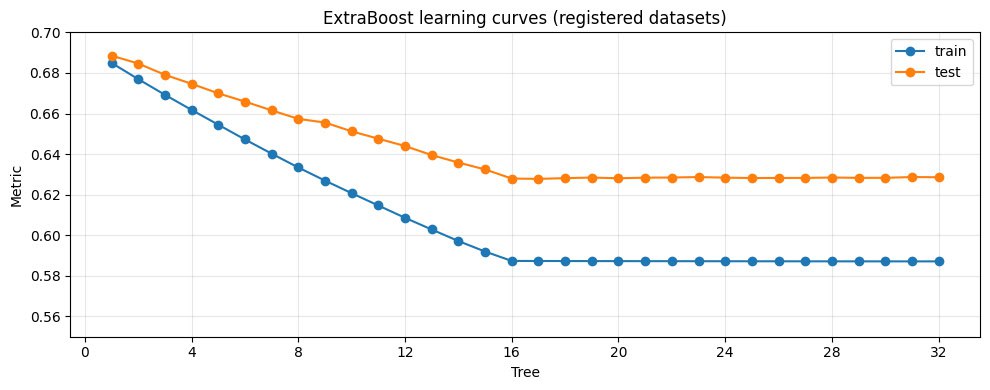
Теперь к графику. Это learning curve: зависимость loss от числа стадий (сколько деревьев уже добавлено в модель). Изначально я рисовал его для отладки. Ожидал падение loss на первых 16 шагах, но первые результаты не совпадали из-за нескольких багов. Сейчас кривые выглядят разумно, но есть несколько интересных деталей.
Loss на train падает на шагах 1…16, затем почти перестает уменьшаться.
Для точек 1…16 train-loss стабильно снижается. После этого почти останавливается - ровно то, что я и ожидал.
На каждом этапе используется decision stump (дерево высоты 1), то есть по сути один признак на шаг. Каждый новый признак может добавить информацию и снизить loss. Когда полезные переменные заканчиваются, выжимать уже нечего.
Разрыв между train и test очень большой.
Я пока не до конца понимаю природу этого gap. Снаружи это выглядит как переобучение.
Интересно прогнать тот же сетап с другими параметрами и проверить, можно ли gap уменьшить (learning rate, регуляризация, subsampling, minimum leaf size - стандартные ручки).
Странный плоский участок test-кривой около шагов 8→9.
На train loss уменьшается на каждом шаге. На test между 8-й и 9-й точками - почти горизонтальный участок. Почему?
Первая гипотеза: первые 8 деревьев в основном используют одну группу признаков, а примерно на шаге 9 модель впервые переключается на другую. Тогда следующий вопрос - почему эта группа хуже обобщается? Признаки слабее, шумнее, сильнее коррелируют или как-то странно взаимодействуют с train/test split?
Столько интересных вопросов.