GBDTE: LogLoss dataset
My approach with the synthetic MSE dataset was successful. I created it, and all experiments gave me quite expected results. The next frontier is a synthetic dataset for testing the logloss function.
This is important for me because I started with this problem, and I want a clear demonstration, especially on synthetic data, that this approach works and that we can improve the stability of our model by incorporating time.
So I started with the same approach my friend and I used almost ten years ago when we published our article. We created a dataset with everything binary: a binary target and binary features. That means all regular features used for splits and the target can be either 0 or 1. The secret ingredient is time: a value in the range from 0 to 1, and a time‑dependent basis [1, t]. The goal of the model is to find weights w1 and w2 so that (w11 + w2t) is the best possible score, which minimizes logloss on this dataset.
To make things interesting, we introduce time dependence into the dataset’s statistical properties. I decided that it’s convenient to make the lift time‑dependent.
Let’s stop here for a moment and discuss this term. We can calculate the target average over the whole dataset, and then over a group selected using a factor. Lift is the ratio of the average target over the selected subset to the average target over the whole dataset. My idea is to make this lift change over time.
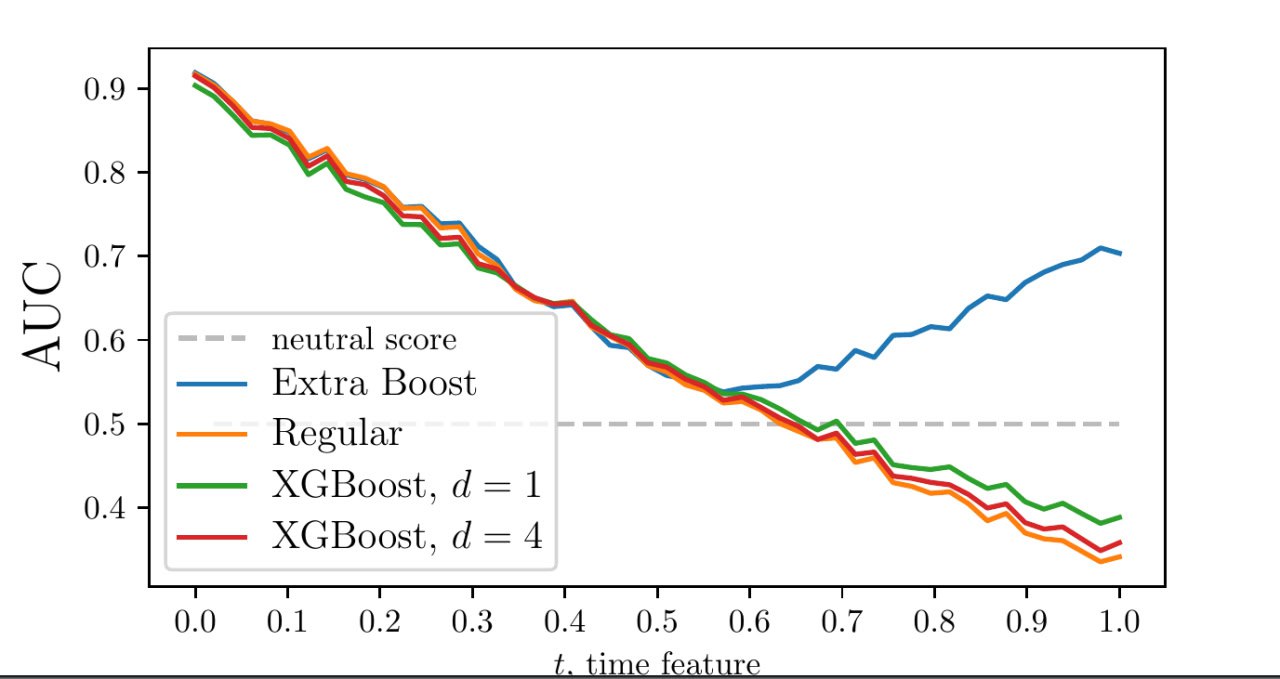
There are two groups of static factors: f1..f8 with increasing lift and f9..f16 with decreasing lift. In the original setup the picture was slightly asymmetrical, and the points where the lifts were equal to one for the two groups were separated, but this time I set the dependencies gamma_up = 0.5 + t and gamma_down = 1.5 - t.
I expected to get a picture similar to what we had in our article, but this time I wasn’t as lucky as we were nine years ago. The picture was different. I have no idea why, and now I’m digging deep into the theory of time‑dependent binary datasets.