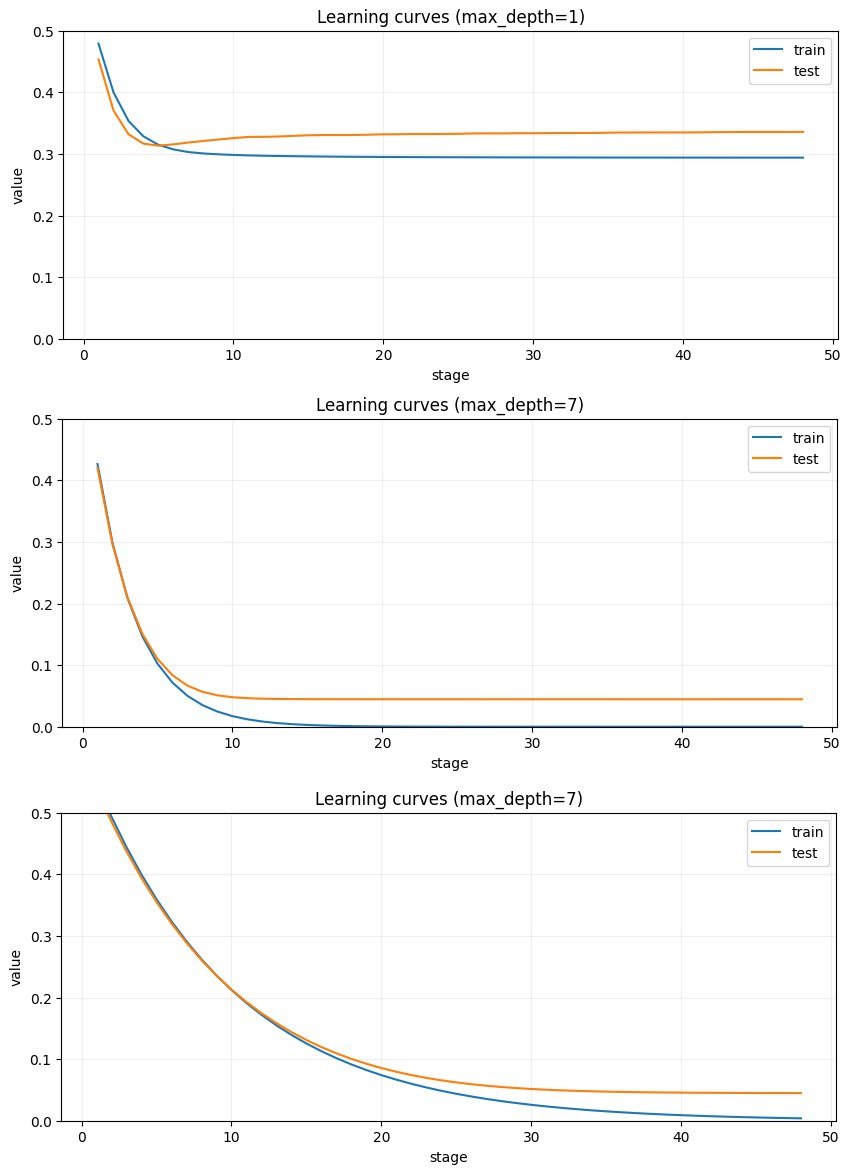
Big MSE dataset. Depth of trees.
There are 128 groups in the Big dataset. And to distinguish them perfectly, it's necessary to use exactly 7 binary features. Why is it so? Because when we add one more level to a decision tree, we change one leaf into two, replacing it with a decision rule. So, if we start with one root and build 7 levels over it, we will have exactly 128 leaves—one leaf for each group.
This illustrates a common phrase about GBDT: "Height of trees is the number of factors we want to work together." I have always heard this phrase, but it was just a theory for me, because in real‑world datasets you have no idea how many factors should work together.
In this dataset we know the exact number of factors to work together—7—and we can test that intuition. And that's exactly the story these three plots are telling us. At the top—trees have only two levels. The model has a limited ability to learn, and we see classic learning curves: the model grasps some generic knowledge and both train and test curves go down. Then it starts to learn noise and the test curve goes up. We can see that, because of the low depth, it can't fit the train set with good quality. It's exactly what we saw in the previous post on the plot "predicted values on train data."
If we check the lower graph, we can see that with depth 7 the MSE becomes much lower and we see a better correspondence between the dataset and the model's inference.
The third image is about the learning rate. lr for upper plots is 0.3 and for the lower 0.1 You can see that the learning curves are less steep. But it doesn't help the asymptotic value of the train curve. When points are wrongly attributed to groups in the initial steps, there is no way to re‑attribute them later.