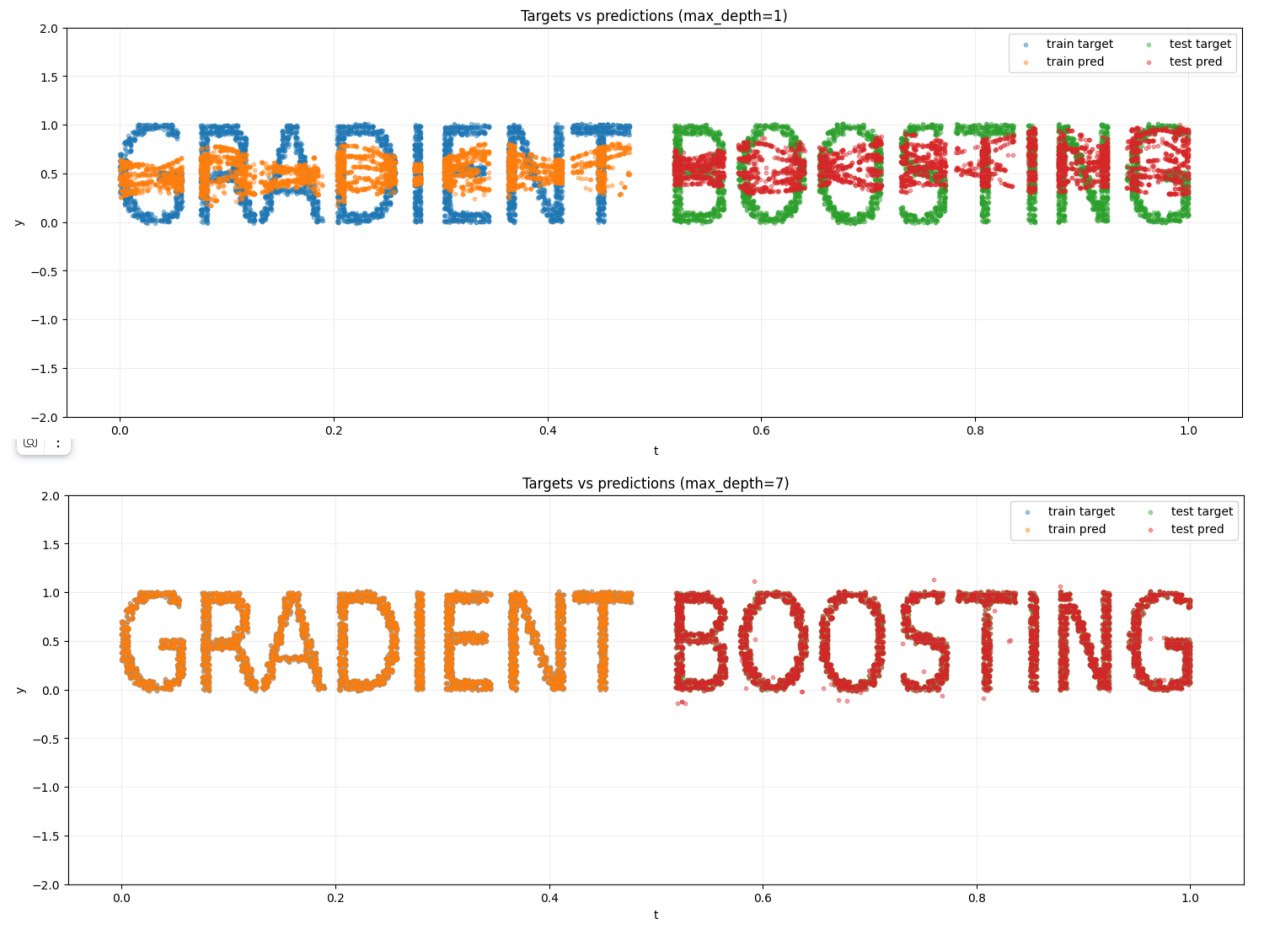
Big MSE dataset for GBDT
In the previous post I demonstrated a small dataset that shows how GBDT works. Now I want to present you quite a big one. There are 10 000 points in it.
I wasn't happy with the quality of the text in the small dataset, so I decided to repeat the algorithm and take more points this time.
While it's quite hard to set many points with a pen, it's easy to ask an iron friend to sample them.
At this point I got stuck for a while with an unexpected problem: I didn't like the fonts. I work in Linux, and mostly fonts don't bother me. Until now. I wanted a nice and interesting font for this task. I have no clue what "interesting" means here—probably a fat, rounded font. I don't know. And then a strange thing happened. When I googled something like "try different fonts online tool", I got nothing. Probably I was banned by Google that day, or I was extremely unlucky, but all the pages I came up with were non-functional or solved some other problem. At last, somehow I got to the... ta-da... fonts.google.com page. But the chain of thought wasn't straight.
Then progress started to go faster. My iron friend quickly rendered the title and scattered 10 000 points across it. Separation into components wasn't hard either. So I ended up with a dataset of 10 000 points separated into 128 groups.
Let's pause here. There's quite an interesting thing about tree height and the number of groups. I want to talk about it slowly and clearly, so let's do it in the next post.