


The Absolute Evil of Default Parameters
Default parameters are evil. Seriously. It’s very convenient evil—so convenient that it crawled into my library.
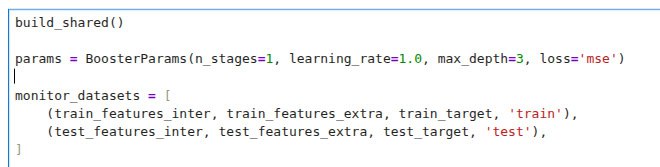
On the first image there is a call to train a model with:
🐴n_stages = 1: one step of boosting (one tree)
🐴learning_rate = 1.0: jump immediately into the minimum of the current parabola
🐴max_depth = 3: use three static variables to separate objects into groups (8 groups)
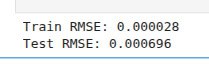
And that seems to be it. So why do we have a non-zero loss? No clue.
God bless ChatGPT. I uploaded the dataset and explained the hypothesis: there’s something odd—try to find the best fitting of extra parameters to the target in each group defined by static features. Then I went to brush my teeth. When I was back, the answer was ready: the dataset is OK, MSE is about 1e-32—zero in terms of double precision.
I scratched my head, zipped my whole repository, uploaded it to ChatGPT, and asked: “Find me the source of 0.0007 RMSE.” Then I started my daily English routine. Fifteen minutes later the answer was ready:
F**ING DEFAULT PARAMETERS
My iron friend dug out this line:
🐴reg_lambda: float = 1e-4
This L2 regularization parameter forced the model to miss points in the training dataset and caused that small but annoying mismatch.
I can imagine myself trying to debug this. My iron friend saved me about two days of checking different parts of my system again and again. And, probably, everything would have been paused - again.