Titanic - Machine Learning from Disaster
I want to close my gestalt. I invented a new ML method, I'm working as ML engineer for 9 years, I taught ML in GoTo school and in Russian Armenian University. But I have never submitted Titanic from Kaggle. Let's try to build our own approach. I think it's always interesting to start from scratch, build your own solution and only then read work of others.
Kaggle
It's a famous platform for machine learning. There is plethora of datasets for different tasks. You can find datasets for regression, classification, ranking, whatever. Kaggle provides free GPU resources for training your models, it allows you to check the quality of your solutions, compete with best ML geeks of our planet. "Grandmaster of Kaggle" is the title you want to have in your CV. So, not a bad place to hang around.
Titanic
13 years ago (what a number!) The Competition was published. Nowadays it's a good tradition to start ML lessons with this dataset. Why? Because:
🛳 It's a binary classification task
🛳 you can train your grasp of precision, accuracy, recall, ROC, ROC AUC
🛳 a lot of missing values
🛳 multimodal data (strings + numbers)
Data
On the data page one can check dataset's structure. It's split on two parts: training part and test part. You are to train model on your data, then apply the model to test data and submit it. Platform will check your results and give you feedback. Let's check fields:
target
☠️ survived - target field, 1 for survived (38%), 0 otherwise.
features
🛂 PassengerId — Unique identifier for each passenger. Not used as a predictor.
🏛Pclass — Ticket class: 1 = 1st (upper), 2 = 2nd (middle), 3 = 3rd (lower). Proxy for socio-economic status.
👺Name — Passenger name. Can be used to extract title (Mr, Mrs, Miss, etc.) or family.
👧🏻 Sex — Biological sex (male / female). Strong predictor of survival (“women and children first”).
🧙🏿♂️ Age — Age in years. Fractional if under 1. Has missing values.
👩❤️👨 SibSp — Number of siblings or spouses aboard (Sibling + Spouse). Discrete count (0–8).
👨👩👦 Parch — Number of parents or children aboard (Parent + Child). Discrete count (0–6).
🎫 Ticket — Ticket number. Often alphanumeric; can be messy for modeling.
💲 Fare — Passenger fare paid. Continuous; may correlate with Pclass and Cabin.
🏡 Cabin — Cabin number. Heavily missing; when present, deck/position may be informative.
🧳 Embarked — Port of embarkation: C = Cherbourg, Q = Queenstown, S = Southampton.
EDA
It's always a good idea to check your data. You can understand, how full they are and how informative they are.
🏛Pclass
No missing values, three values with frequencies:
1 216
2 184
3 491
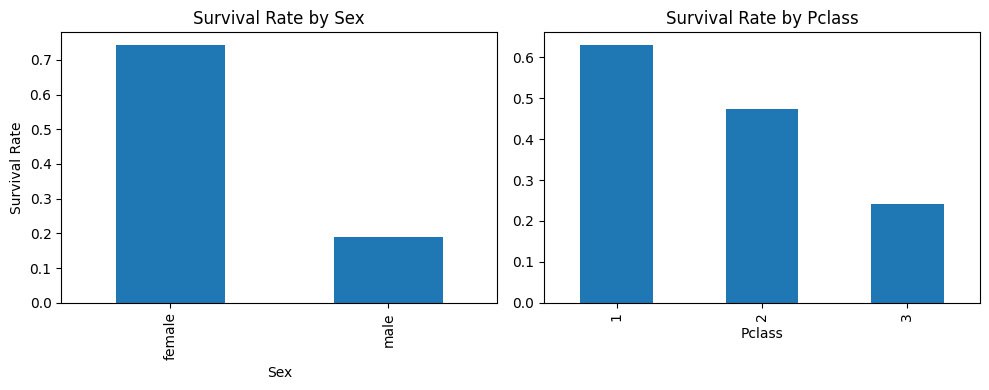
We can calculate average survival rate for all three classes:
1 63%
2 47%
3 24%
Now we can recall that average survival rate is 38%. So, first class highly votes for the survival, second class slightly votes for survival and third class highly votes against survival.
👺Name
It's a good quiestion, whether name contains some information for survival at all. Let's check. I want to use hash trick technique and figure out. Experiment with hash trick demonstrated that Name feature contains information and gives 62% ROC AUC. So I dove into this field deeper. It turned out that it has format like
Futrelle, Mrs. Jacques Heath (Lily May Peel)
I checked distribution of survived for different titles and it is a good feature:
Master 0.575000 40
Miss 0.702703 185
Mr 0.156673 517
Other 0.724832 149
👧🏻 Sex
definitely a strong feature, it is on the picture
🧳 Embarked — Port of embarkation: C = Cherbourg, Q = Queenstown, S = Southampton.
Three different values, strong uplift => valueable feature
I'm going to continue this exploration. I would like to see that this topic is interesting. Please vote with 🔥 if you like it.
Jupyter Lab
github: eda