From uplift to logit
Where we are
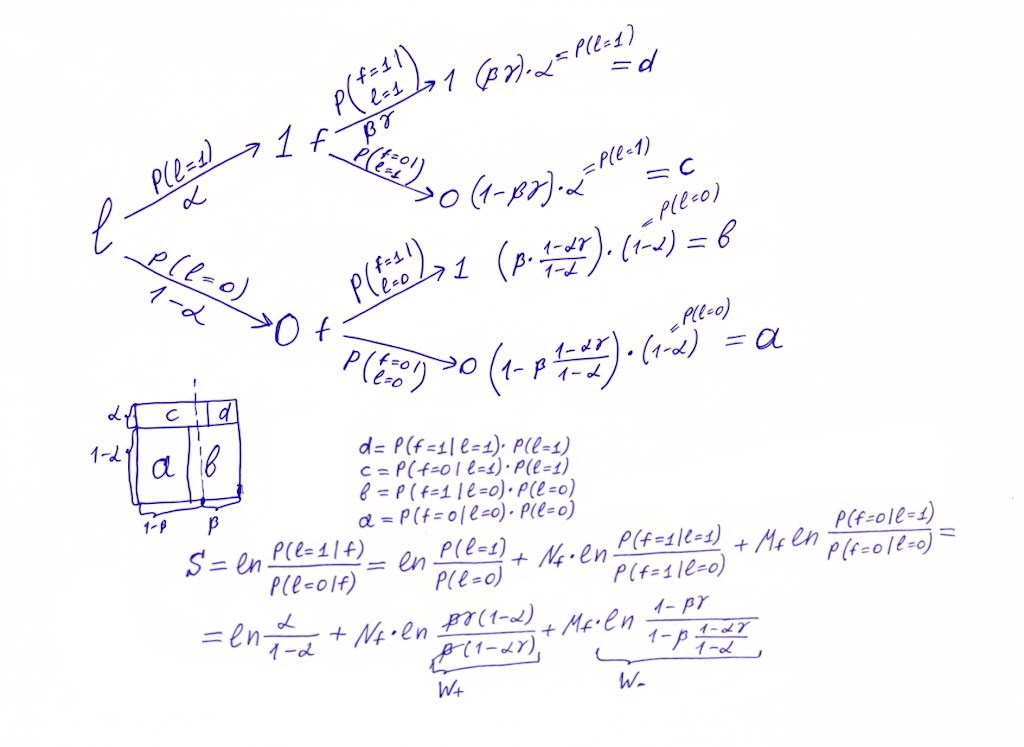
In the previous post we started to build a bridge from uplift to a score, which lets us solve binary classification problem. What we achieved:
⚗️ calculated probabilities for all combinations of binary feature f and target L
⚗️ wrote a score expression for S as logarithm of conditional probabilities fraction
Notation
⚗️ L - a binary target, 0 or 1 values (l in picture)
⚗️ r - a binary feature, 0 or 1 values
⚗️ α = P(L=1) - probability of target to be 1 or average value of target
⚗️ ϐ = P(f=1) - coverage, probability of feature to be equal 1, or average value of feature
⚗️ γ = P(L=1|f=1)/P(l=1) - uplift, gain in target we have when selected subset with f = 1
⚗️ S - score for ideal model to predict target
Problem statement
For given α, ϐ, γ:
🦐 create a dataset with non-stationary uplift γ
🦐 create baseline S for target prediction
Increment
For me these conditional probabilities are terra incognita. I don't have solid intuition, what is right and what is wrong. So, I was wanted a small sanity check for all this complex for me math. And test is quite simple: γ=1 means that factor doesn't give new information about target. In this case weights for this factor should become 0. In the previous attempt it wasn't obvious at all.
This time I slightly changed notation and used conditional probabilities instead of absolute one. And it is totally obvious now that when γ=1, expressions under logarithms become 1, logarithms are equal to 0 and therefore, expressions with N and M (number of ones and zeroes in sets of factors) goes away. It means that factors are not important, exactly what we assumed taking γ=1. Now I'm quite confident in this result, so let's dive deeper.
Outcomes
🦐 we have watertight expressions for dataset generation for arbitrary γ
🦐 there is an expression for the optimal model S
🦐 case γ=1 checked and S behave as it expected
🦐 expression for S is a bridge from probabilities to logistic regression model
🦐 it’s a universal approach — we can try it in the wild